
El cerebro no solo escucha música se convierte en el ritmo.
https://www.earth.com/news/our-brain-doesnt-just-hear-music-it-becomes-the-rhythm/
Nuevos hallazgos sobre modos de escucha
https://www.sciencealert.com/scientists-just-found-a-hidden-set-of-modes-in-the-human-ear
Un nuevo estudioo lo confirma: Vista y escucha son sentidos que se complementan.
Hemos comentado al cansancio sobre las pruebas ciegas para evaluación de un eq uipo de audio o sistema, es decir sin ver, la lógica de quienes defienden tal prueba es que no se vicia o corrompe el juicio auditivo con la vista, pero ¿Y si los sentidos funcionaran en conjunto para un mejor proceso cognitivo y sensorial? ¿Imaginan saborear algo sin tener bein el olfato ? ¡Horrible! Es como cuando se tiene gripe.
Resumen: Una nueva investigación revela que las personas que experimentan pérdida de visión antes de los 10 años tienen más dificultades para juzgar la distancia del sonido en comparación con aquellos que pierden la vista más adelante en la vida. Esta dificultad para percibir la ubicación de los sonidos tiene importantes implicaciones para la seguridad y la navegación.
El estudio destaca la necesidad de soluciones sanitarias personalizadas para aquellas personas con pérdida temprana de visión para mejorar su calidad de vida.
Hechos clave:
La pérdida temprana de la visión afecta la capacidad de juzgar con precisión las distancias del sonido.
Los participantes con pérdida temprana de la visión percibieron los sonidos cercanos como si estuvieran más lejos.
El estudio subraya la importancia de comprender la dependencia sensorial en personas con pérdida de visión.
https://neurosciencenews.com/vision-loss-sound-distance-26470/


La música sincroniza los cerebros de los artistas intérpretes o ejecutantes y su audiencia
Increíble, lamentablemente ya no pude tener acceso al artículo.
https://www.scientificamerican.com/article/music-synchronizes-the-brains-of-performers-and-their-audience/
Cuanto más disfruta la gente con la música, más parecida es su actividad cerebral a la del músico
2 de junio de 2020 - Robert Martone

Los neurocientíficos recrean la canción de Pink Floyd a partir de la actividad cerebral de los oyentes
La inteligencia artificial ha convertido las señales eléctricas del cerebro en rock clásico algo un tanto confuso.
https://www.scientificamerican.com/article/neuroscientists-re-create-pink-floyd-song-from-listeners-brain-activity/
Thorsten Loesch AMR/ifi: El audio high end va muriendo poco a poco.
Gran artículo que gracias a Josep Busquets de Amigos Hi-Fi podemos leer en español.
Lamentablemente la conclusión es una que en lo personal comparto, el high end muere, pues no ha podido conectar con generaciones jovenes desde hace 20 o 30 años, solo somos los mismos haciendo "negocio" y los mismos compradores, reflejando todos el paso del tiempo.
The Show Must Go On por Thorsten Loesch (amigoshifi.com)

El High End Audio está teniendo una muerte tranquila y digna (espero), ya que durante muchos años no ha conseguido conectar con las generaciones más jóvenes. En cada feria solíamos ver a los mismos expositores (tal vez con una nueva empresa) y a los mismos clientes, sólo que un poco más viejos y con un aspecto más tosco, cambiando sus enérgicos andares de los 90 por bastones en los 00 y andaderas en los 10 y no espero volver a ver a muchos de los habituales, cuando, es decir, si alguna vez, las ferias High End vuelvan al mundo real después de que la epidemia y las cuarentenas hayan pasado.
¿Se preguntarán si me he hecho rico? No, todavía no. Por suerte, tampoco soy más pobre que antes, ya que hay mucha más gente que ha perdido más dinero con el audio de alta fidelidad que el que ha hecho.
High Fidelity Sound, un buen sitio para iniciar
No es muy común ya encontrar sitios así, al inicio del web, cuando empezaba a ser más usado por ahí de la segunda mitad de los 90s eran muy comunes este tipo de sitios formativos, toda una generación se lanzó a aportar su saber, pero poco a poco el web se hizo lugar para tonterías y egos, anuncios e información difusa. Por eso mismo da gusto encontrar este sitio que informa y educa.
Y revisando a detalle más gusto me da encontrar que se ofrece en español y más aún que es un proyecto de estudiantes de Electrónica y Computación del Liceo Franco Mexicano en conjunto con TI.
Viendo este nivel de interés me ha hecho contactar ya al profesor y alumnos por si desean conocer más del Hi-Fi nacional y hacer una presentación ahí por parte de Armonia AV y Aletheia AV.
http://hifi.vije.net/hifi/index/english/index_us2.html

Y revisando a detalle más gusto me da encontrar que se ofrece en español y más aún que es un proyecto de estudiantes de Electrónica y Computación del Liceo Franco Mexicano en conjunto con TI.
Viendo este nivel de interés me ha hecho contactar ya al profesor y alumnos por si desean conocer más del Hi-Fi nacional y hacer una presentación ahí por parte de Armonia AV y Aletheia AV.
http://hifi.vije.net/hifi/index/english/index_us2.html
Relación de impedancias en interconexión de equipos:
De modo simlificado, que la impedancia en el equipo que recibe sea por lo menos 10 veces mayor que la impedancia de salida del otro equipo a conectar.









AudioControl es adquirida por AAMP Global.
Es un hecho que la consolidación o compactamiento corporativo del mercado del audio y Hi-Fi sigue, M&A como nunca, Audio Control ahora es parte de AAMP Global. En cierta forma ya Audio Control quedó emparentada con Stinger.

Escacés de bulbos... o mejor sobre el exceso de anuncios.
Iba a comentar sobre esta situación con los bulbos, ahora que la invasión rusa y las acciones y reacciones han cerrado la venta de bulbos rusos hacia el mundo.
Hace años decía que no me gustaba el audio a bulbos por que mayormente se fundamentaba en productos provenientes de países con dudosa marca en diversos aspectos, como los son China y Rusia.
Pero más que el tema mismo de podcast en la revista Part Time Audiophile,
me asombra negativamente ver como se hace casi imposible leer en esas publicaciones, están atiborradas, saturadas de anuncios al punto, por lo pronto para mí que leer algo se hace tedioso, molesto y hay demasiados distractores como para seguir una lectura seriamente. Creo que algo deben hacer al respecto.
 |
Super regalo ! Revistas Stereo alemanas gratis online.
https://archive.org/details/stereo-magazine/stereo-magazine-issue-01/

El CD no estaba muerto andaba de parranda
Ya no es novedad a estas alturas que el CD ha repuntado un poco en ventas tras más de una década en declive, y si bien lo daban por muerto "los expertos" hace apenas unos 6 a 12 meses la verdad ha sido distinta, a mi parecer no se puede matar un formato:
- con una base instalada tan amplia es decir un catálogo tan grande acumulado en 40 años
- un formato que aún hoy es el referente de calidad digital estandarizada más fácil de reconocer
- y tampoco cuando es un formato para el cual han aparecido bastantes reproductores en meses recientes.
No puedo decir cual sea su futuro definitivo pero muerto por lo pronto es claro que no lo está.

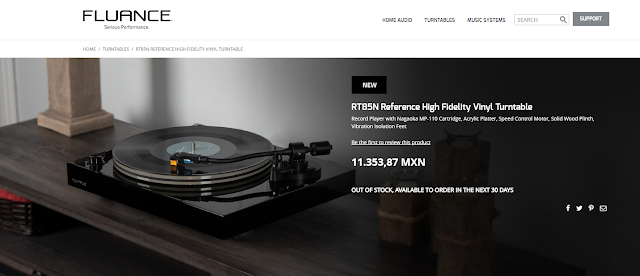
¿Ofrece Fluance uno de los mejores valores de compra en tornamesas?
Desde hace años he visto a esta marca, al inicio la supuse un competidor más sin alma, enfocado en vender masivamente y no más, sin embargo ha cambiado mi parecer viendo como han ido ajustando y mejorando su oferta para el mercado de entrada y medio bajo. Este producto la Fluance RT-85N además de tener un diseño clásico entre productos de este tipo ya con un buen nivel de calidad, tener la correa externa sobre el perímetro del plato además ofrece el fonocaptor Nagaoka MP-110.
Me parece en general un producto interesante que fácilmente se colocaría a mi parecer por sobre propuestas e marcas como TEAC, Onkyo, Pioneer, Crossley y un amplio etc. Ponienod posiblemente en apuros a algunos modelos entry level de marcas más especializadas como Orbit, Rega, Project y otras similares.
Robert Koda K-15 EX preamplificador de linea
Extraordinario preamplificador, diseño minimalista y aspecto sobrio y de buen gusto, estupenda selección de partes, circuito balanceado.
Para cuando buscas un preamplificador que destaque por sobre otro y dispongas de solo 60,000 Libras para su compra 😉.
- Type: Line level preamplifier
- Inputs: Five pairs true balanced (pin 2 is Hot). Five pairs RCA
- Output: Two pairs RCA, Two pairs true balanced (pin 2 wired Hot)
- Voltage gain: +8dB at maximum volume
- Signal to noise ratio: 114dB A-weighted at 1Vrms output, 147dB at full output
- Frequency response: 20Hz–20kHz ±0.05dB
- Maximum output: 30Vrms single-ended, 60Vrms balanced
- Input impedance: 50kΩ single-ended, 50kΩ per phase balanced
- Output impedance: 60Ω Single ended, 30Ω per phase balanced
- Total harmonic Distortion: Less than 0.0003% at 2V RMS out, 1KHz, balanced input
- Dimensions (W×H×D): 389 × 158 × 385mm
- Weight: 29kg

Haniwa, desde Japón
Me encontré con este muy interesante fabricante de fonocaptores, tornamesas y accesorios y planificadores para fono. Por si alguien tiene algunos miles de dólares excedentes para destinarlos a estos productos parece una compra interesante.

Ultra Low Impedance Cartridges
The high end audio world is made up of “components”. Some companies design and build cartridges, some build phono preamplifiers, others build preamplifiers, amplifiers or speakers. It is rare that a company and a designer considers an entirely new “true systems” approach to audio reproduction, and starts from scratch with a “clean sheet of paper”. Dr. Kubo has done this with Haniwa … it was designed as a totally new approach to audio. While he was designing the analog front end of the Haniwa audio system, he developed new technology that overcomes problems that exist in most other systems on the market while extracting all of the music from the record groove with pristine accuracy and detail. It all starts with the sensor used to extract the music from the groove … the cartridge. In considering the cartridge pick-up system, Dr. Kubo has developed ultra-low impedance cartridges based on a current loop system as opposed to most voltage based systems.
Suscribirse a:
Entradas (Atom)